Overview of SLATE Platform Internals and Security
Chris Weaver
March 20, 2020
Introduction
This document describes the logical components of the SLATE platform and how they relate to each other. Major data flows and security mechanisms are described. Numbered sections of this document correspond to the labels in Figure 1.
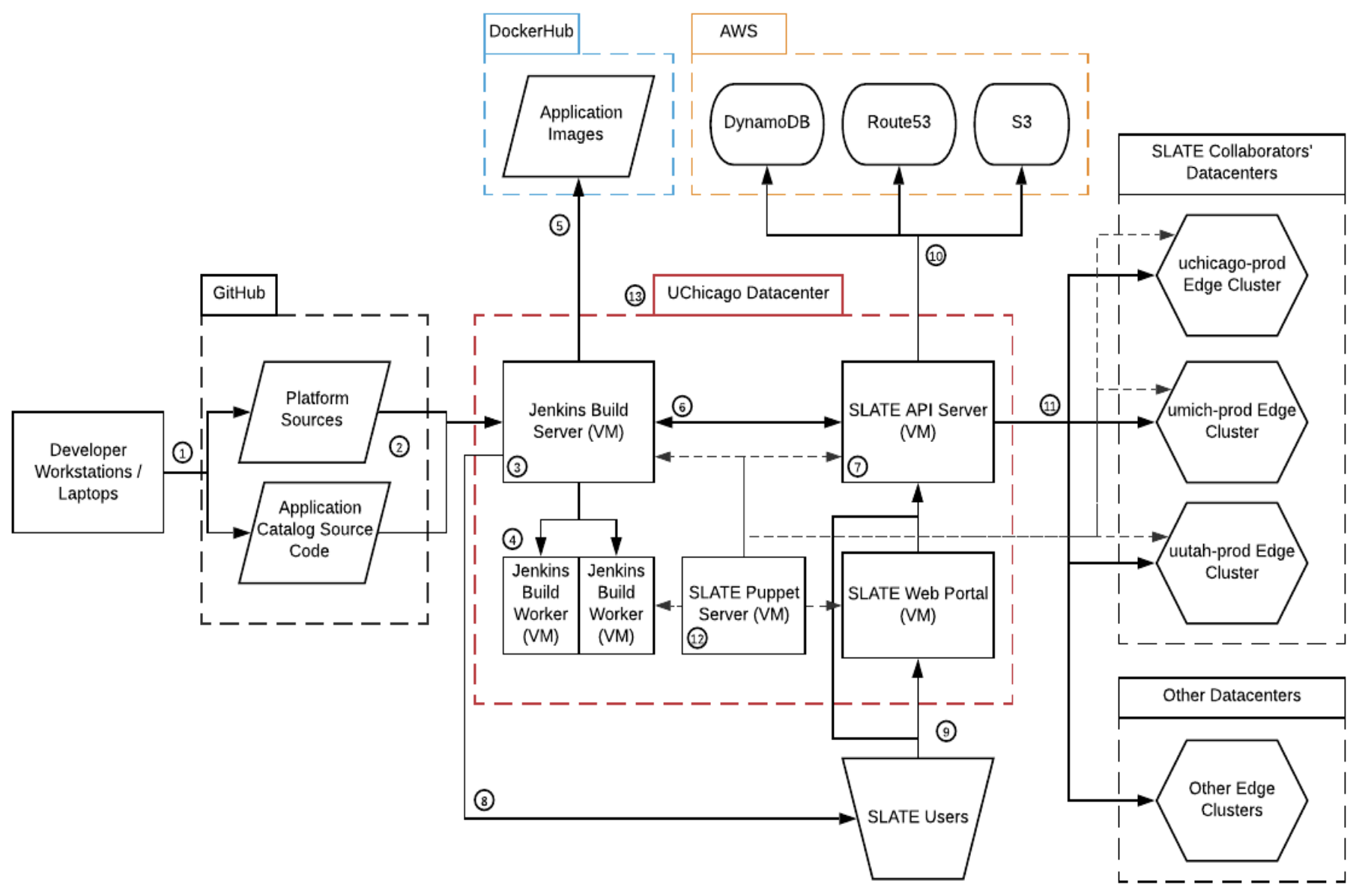
1. Source Code Updates
Core developers modify source code, and push to GitHub. This can be either directly writing new code, or choosing to accept code submitted by the community in the form of ‘Pull Requests’. Only SLATE team members who belong to the ‘slateci’ GitHub organization have the access to update code in this manner; authentication is handled by GitHub.
2. Code Update Notifications
GitHub automatically notifies Jenkins (via a GitHub ‘webhook’), which pulls updated code. This notification has little semantic content itself; only the label for the repository in which it claims changes have occurred is used, and it must match one of the repositories already configured in Jenkins. Thus, spurious messages can waste Jenkins resources by causing it to check for new code unnecessarily, but cannot be used to insert or modify code to be built. Ideally, these notifications should only be accepted from GitHub; this is difficult to implement as an IP-based firewall rule as GitHub uses many hosts, but GitHub does support an HTTP header ‘secret’ mechanism (i.e. a password) which can be used for verification. (Such verification is not currently in use).
3. Jenkins Build Server
The Jenkins build server (master) runs both Jenkins to automatically build updated code into artifacts, and nginx, which is responsible for serving some artifacts to other parts of the system, including end users.
- Jenkins itself is considered risky to expose, due to the high rate at which vulnerabilities are discovered, and the fact that it must have the capability to execute essentially arbitrary code and to write to the artifact storage spaces. The jenkins web interface is therefore protected by firewall rules to allow only connections from the localhost. Developers wanting to access the interface must make an authenticated SSH connection to tunnel the port. Incoming requests from the GitHub webhook to Jenkins are proxied via nginx, ensuring that only the webhook portion of the Jenkins interface is exposed.
- Nginx listens for HTTP connections on port 80, but responds to all requests with HTTP status 301 and redirects to HTTPS on port 443. HTTPS requests on 443 are served either by serving static files for build artifacts and logs, or forwarding to the Jenkins webhook interface.
The Jenkins Build Server is accessible to a subset of the core developers via SSH. The publication of build logs via Nginx is intended as a replacement for viewing logs in the native Jenkins web interface for members of the community who contribute code, SLATE developers who do not have SSH access, and as a more convenient mechanism for developers who do have SSH access.
It should also be noted that under some circumstances Jenkins will build code supplied by the public: any ‘Pull Request’ submitted to the slate-catalog repository is built to ensure that it is in basic working order. These builds do not lead to artifact publication, and changes to the build scripts themselves are ignored. However, they can produce side effects on the build server, such as the execution of arbitrary commands inside containers which are built. Such containers will never be used directly and read from the build server filesystem generally during building, but they can consume disk space, may do arbitrary computations, upload or download data from/to themselves, and if an escape from the container runtime is possible could lead to unrestricted code execution on the build server.
The Jenkins Build Server is currently a virtual machine, running on the U. Chicago (Maniac Lab group’s) OpenStack system (see section on U Chicago data center), physically on a hypervisor machine located in the Maniac Lab datacenter. It is scanned weekly by the University of Chicago’s InsightVM vulnerability scanner.
4. Jenkins Build Workers
New code (of some types) is compiled on build workers: When the Jenkins master determines that new code should be built, it may fetch and build it itself, or it may instruct one of the build workers to do so. The master connects to the workers via SSH with a keypair, which must have no passphrase in order to be used automatically. It is neither necessary nor desirable that the build workers should accept connections from any machine other than the jenkins master.
The build workers are a pair of Virtual Machines running on the same infrastructure as the Jenkins Master. One runs Alpine Linux in order to more easily produce statically linked binaries for Linux, and the other is CentOS with a clang-based cross compiler to produce binaries for Mac OS.
5. Build Artifact Publication to DockerHub
After a successful build, artifacts are published, with container images being uploaded to DockerHub. Uploads are authenticated using a credential token issued by Docker for the account used only by the Jenkins master. Currently, the token is stored in the default location, in the jenkins user’s docker configuration file. Docker supports other, more secure means of storage, but as the credential must be used programmatically, encrypted storage is probably not a viable option.
6. Application Catalog Update Notifications
When the SLATE application catalog is rebuilt, Jenkins also notifies the SLATE API Server, which updates its application cache. The mechanism is a normal HTTPS request to the SLATE API, authenticated as usual with a token issued by the SLATE API Server. The token is encoded into a script which is present only on the Jenkins Build Server. Currently, no special privileges are required to issue this update request; any authenticated SLATE user may do so. The only effect of receiving this type of request is that the SLATE API uses Helm to fetch the latest catalog data into its local cache. The content of the request itself does not influence which data is fetched or from where; these aspects are inherent to the API Server.
7. The SLATE API Server
The SLATE API Server (VM) runs the slate-service (executable) which implements the SLATE API. It listens on port 18080 for incoming requests from the public internet (see Requests to the SLATE API), and is accessible to a subset of the core developers via SSH on port 22. Because the SLATE API must be public to perform its purpose, IP-based firewall protection is not an option. IP-based restriction of SSH access is possible but not currently implemented.
The SLATE API Server is currently a VM, hosted on the Maniac Lab OpenStack infrastructure. Logs from the API Server are forwarded to a separate syslog server.
8. Users Download the SLATE CLI Client
Users can download the SLATE CLI client from the Nginx server on the Jenkins Build Server. As described above, this connection is protected with TLS. Additionally, SHA-256 checksums are provided along with the client executable tarballs, to allow users to verify that the tarballs are unmodified since they were built. Once the client program has been downloaded, its self-update feature can be used to download newer versions in the same manner, with the install process being automated by the user. It is the user’s responsibility to use the update feature; it does not run by itself based on any schedule.
9. Requests to the SLATE API
SLATE users (application administrators) send requests to the SLATE API to request actions by the SLATE Platform. Requests may be sent either via the SLATE Web Portal or via the SLATE command line client (or, in theory as via any tool capable of generating HTTPS requests). All requests are communicated over HTTPS, which is directly supported by slate-service, and except for a very limited subset, commands for querying the server’s supported API version(s) and operating statistics, require authentication using tokens previously issued by the API server. After authentication succeeds, additional authorization rules, built into the API implementation, are applied to determine whether the requesting user is allowed to request the particular action. All requests are logged, including the requesting user (if authentication was successful), and the origin IP address.
Some SLATE API actions modify only the state of the API (creating and modifying user accounts, changing users’ membership in groups, etc.), while others entail changes in the state of federated clusters (e.g. starting or stopping an application, creating or deleting a secret).
Currently the tokens issued by the SLATE API server are opaque blobs with no internal semantics. Their contents are 64 bits of output of a Cryptographic Random Number Generator. These opaque tokens do not contain an expiration time, but can be revoked at any time by the API server which issued them, which maintains a record of all valid tokens (stored in DynamoDB). Each SLATE user is assigned a unique token.
10. Data Storage by the SLATE API
The SLATE API stores data in three services hosted on AWS: Database records internal to the API are written to DynamoDB, public DNS records are created in Route53, and map data for display on the SLATE website is stored in S3. All communication between the API server and AWS services is over HTTPS, and all requests use the AWS signing process with an AWS token.
In addition to records automatically managed by the SLATE API, DNS records for many components of the SLATE infrastructure (such as the SLATE API server itself, the Jenkins Build Server, etc.) are manually managed in Route53.
Many lines of communication and data flow within the SLATE platform depend on correct and reliable DNS. This could be threatened either by unauthorized modification of data stored in Route53, or by the presentation of false records to clients performing DNS lookups. Route53 does not support DNSSEC, which could be used to protect against the latter issue.
Only public data is stored in the S3 bucket used by SLATE; this is specifically intended to be readable by users who visit the main SLATE website (via Javascript embedded in that page which draws the world map of SLATE clusters). No other data should be stored in this location. The keys for writing to this bucket are kept on the SLATE API server VM, and made available only to team members who administer this system.
11. Commands to Federated Clusters
The SLATE API sends commands to federated clusters to start, stop, and inspect application instances (and other related Kubernetes commands). These commands use the Kubernetes API (specifically, the kubectl tool for communicating with Kubernetes clusters and Helm). Communication uses HTTPS, and is authenticated using a certificate issued by the target cluster. Each certificate is associated with a Kubernetes ‘ServiceAccount’ on the target cluster to which Role-Based Access Control rules are applied within Kubernetes. These rules allow the ServiceAccount to view certain global data on the cluster, but only to make modifications to objects within particular Kubernetes ‘Namespaces’ created for it to use. No access is permitted to other Namespaces.
12. Puppet Server
The Puppet Server is a VM which runs the puppet configuration management tool. It is currently responsible for managing:
- The Jenkins build server
- The Jenkins build workers
- The SLATE Portal server
- The SLATE API server
- The SLATE API development server
- The SLATE Sandbox server
- The SLATE Sandbox development server
- The uchicago-prod cluster nodes
- The umich-prod cluster nodes
- The uutah-prod cluster nodes
- (Itself)
MWT2 GitLab
The GitLab instance, operated by the U. Chicago Midwest Tier 2 hosts the configuration files used by the SLATE puppet server. This includes the definitions of user accounts which are provisioned onto the machines managed by the puppet server. As a result, a user who has access to set the puppet configuration has administrative control, in practice including SSH access, to all of the managed machines. Configuration in puppet is used to grant the InsightVM vulnerability scanning system run by the University of Chicago access to scan machines located there.
13. University of Chicago/Maniac Lab Data Center
The Maniac Lab data center is located in the University of Chicago Accelerator Building. Physical Access to the datacenter is restricted to Maniac Lab group system administrators, and University of Chicago systems engineers, facilities personnel, and management. Assets in this data center are scanned by the Insight VM installation hosted by the University of Chicago for security vulnerabilities.